

Lost in Machine Translation
Computers are not good at translating Arabic dialects. Here's why.
Have you ever translated an Arabic Facebook or Twitter post only to be baffled by the English result? You’re not alone. Bad Arabic machine translations — translations carried out by a computer — are a common frustration. Arabic is a tough language for computers to figure out because it has dozens of dialects, millions of unique words, and there are many ways to say the same thing.
“Humans learn language through immersion and repetition, constantly absorbing and picking up linguistic cues from our social environment while computers learn using algorithms and data samples that we provide them,” explained Nizar Habash, associate professor of computer science at NYU Abu Dhabi. For computers to produce accurate results, computational linguists need to input more information about the language.
There are quite a few quirks to the process though.
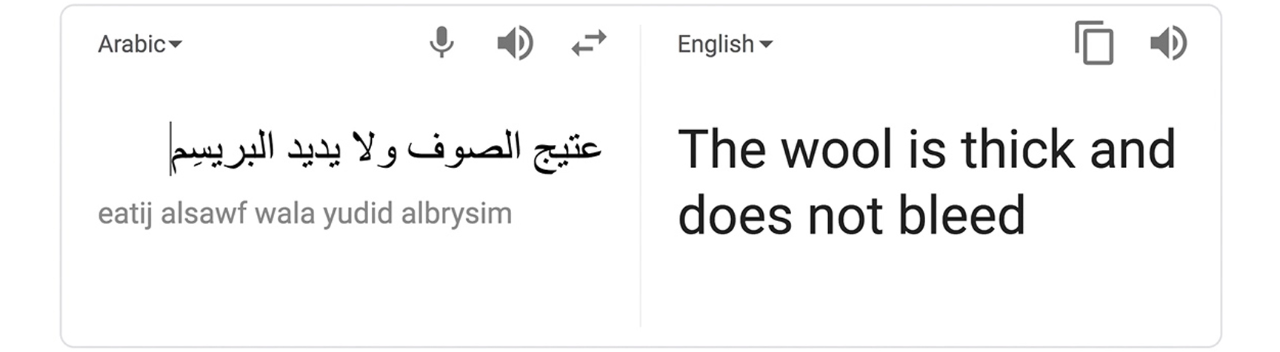
The literal meaning of the above proverb in the UAE Arabic dialect is ‘old wool is better than new silk’, implying that appearances can be deceiving, but the Google translation is way off — only one word is correct. However, Arabic news articles translated by Google usually yield more accurate results. Why the discrepancy?
Humans learn language through immersion and repetition … while computers learn using algorithms and data samples that we provide them.
Habash says computational linguists have access to large collections of parallel English and Modern Standard Arabic (MSA) data that can be used for training machine translation systems. MSA is the form of Arabic used only in news reports and formal communications in Arab countries. But Arabs don’t use MSA in their day-to-day interactions online or in conversation. With over two-dozen dialects in use today on social media, there is a lot of dialectal data, but lack of parallel translations, which explains the wide discrepancy between translations of news articles on one hand versus poetry and dialectal texts on the other.
These challenges present themselves in other applications too. “An Arabic chatbot similar to Siri or Alexa should ideally be able to understand any dialect and accent but they don’t,” explained Habash. “Compared to English or Chinese, research on Arabic chatbots is still in its early stages.”
Compared to English or Chinese, research on Arabic chatbots is still in its early stages.
Habash and his research team at NYU Abu Dhabi are creating new and updated datasets, algorithms, standards, and tools for computers to learn Arabic. But it’s a monumental task.
One of the problems to overcome is the use of diacritics; optional signs above or below a letter used to indicate short vowels, which can alter the meaning of a word depending on where they’re positioned. These signs are often dropped when writing and hard to interpret if there’s no context. MSA words also have, on average, 2.7 core meanings. Some could have even more; a word like بين / bayn can mean different things based on how it’s read:
- bayn - between/among
- bayyana - he clarified
- bayyin - clear
- biyn - Ben (name)
- biyan - in Yen (Japanese currency)

An additional roadblock for computational linguists is that Arabic verbs can have up to 5,400 conjugations while English verbs typically have five (such as the verb to go: go, gone, went, goes, and going). Furthermore, Arabic dialects do not have standard spelling rules.
NYU Abu Dhabi is tackling these challenges in multiple ways by creating datasets that include a collection of over 100 million Gulf Arabic words (Gumar Corpus), building comparative sets of sentences in different Arabic dialects from 25 cities paired with their English-French-Arabic equivalent to be used as the foundation for machines to identify dialects, and manually disambiguating 200,000 words from a number of Emirati Arabic online novels.
In the context of multilingual social media, the world’s understanding of Arabs and their culture is tied to the quality and reliability of Arabic machine translation. As Arabs, it’s in our interest to make sure our voice is well presented.
Habash is also developing a toolkit that will provide solutions to basic problems such as identifying dialects and exploring how words are structured or formed. This will enable other researchers to work on different kinds of applications that can expand Arabic artificial intelligence capabilities similar to work done in major languages such as English, Chinese, and French.
Arabic has to start keeping up with other languages, he says, not just from the perspective of technology but also to ensure that language is not a barrier in any way.
“In the context of multilingual social media, the world’s understanding of Arabs and their culture is tied to the quality and reliability of Arabic machine translation. As Arabs, it’s in our interest to make sure our voice is well presented.”



